はじめに
- EBSの初期サイズを増やしすぎた。
- ボリューム拡張で増やしすぎた。
見積もりのミスで、こういうときが偶にある。
特に規模感が見えないプロジェクトではありがち…。
今回は、EBSのボリュームを縮小するということをやってみる。
環境
AWS EC2 (t4g.nano)シチュエーション
下記のような状況でのシミュレーションを行う。
- AWS EC2インスタンスを作成
- EBSを12GBでつくった!けど8GBで良かった…。
準備
シチュエーションを再現するためにインスタンスを作成する。
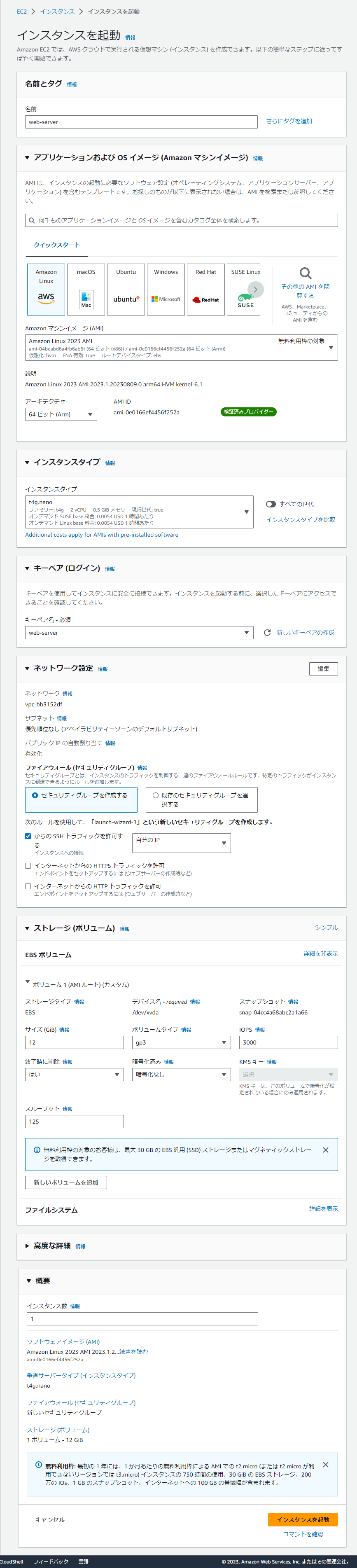
EC2インスタンスの作成
| 項目 | 設定値 |
|---|---|
| 名前 | web-server |
| OS | AmazonLinux2023 AMI |
| アーキテクチャ | 64ビット(Arm) |
| インスタンスタイプ | t4g.nano |
| キーペア | web-server(新規で作成) |
| セキュリティグループ | ssh, http (自分のIPのみ) |
| ストレージ | 12GB (gp3) |
SSHログイン
, #_
~\_ ####_ Amazon Linux 2023
~~ \_#####\
~~ \###|
~~ \#/ ___ https://aws.amazon.com/linux/amazon-linux-2023
~~ V~' '->
~~~ /
~~._. _/
_/ _/
_/m/'
[ec2-user@ip-172-31-45-77 ~]$ ログインできた!
確認のためにApacheをいれておく
sudo dnf install -y httpdsudo systemctl start httpd
sudo systemctl enable httpdIPにアクセスして、 It works! が表示されることを確認する。
EBSの縮小 手順
おおまかな流れは下記になる。
※もし本番環境など重要な環境で作業する場合は、2の手順の後に対象のインスタンスのAMI を作成したほうが良い。
- 新ボリュームを作成する。
このボリュームは、後のルートボリュームとなるので 8GBとする。 - 作業用のインスタンスを作成する。
- 対象のインスタンスを停止し、ボリュームをデタッチする。
- 作業用のインスタンスに新ボリュームと旧ボリュームをアタッチする。
- 作業用のインスタンスにログインし、旧ボリューム(12GB) と 新ボリュームのディスクで同期を取る。
- 作業用のインスタンスを停止し、旧ボリュームと新ボリュームをデタッチする。
- 対象のインスタンスに新ボリュームをアタッチし、ルートボリュームとして起動するようにする。
ボリュームを作成する
サイドメニュー > ボリューム から ボリュームの作成を選択する。
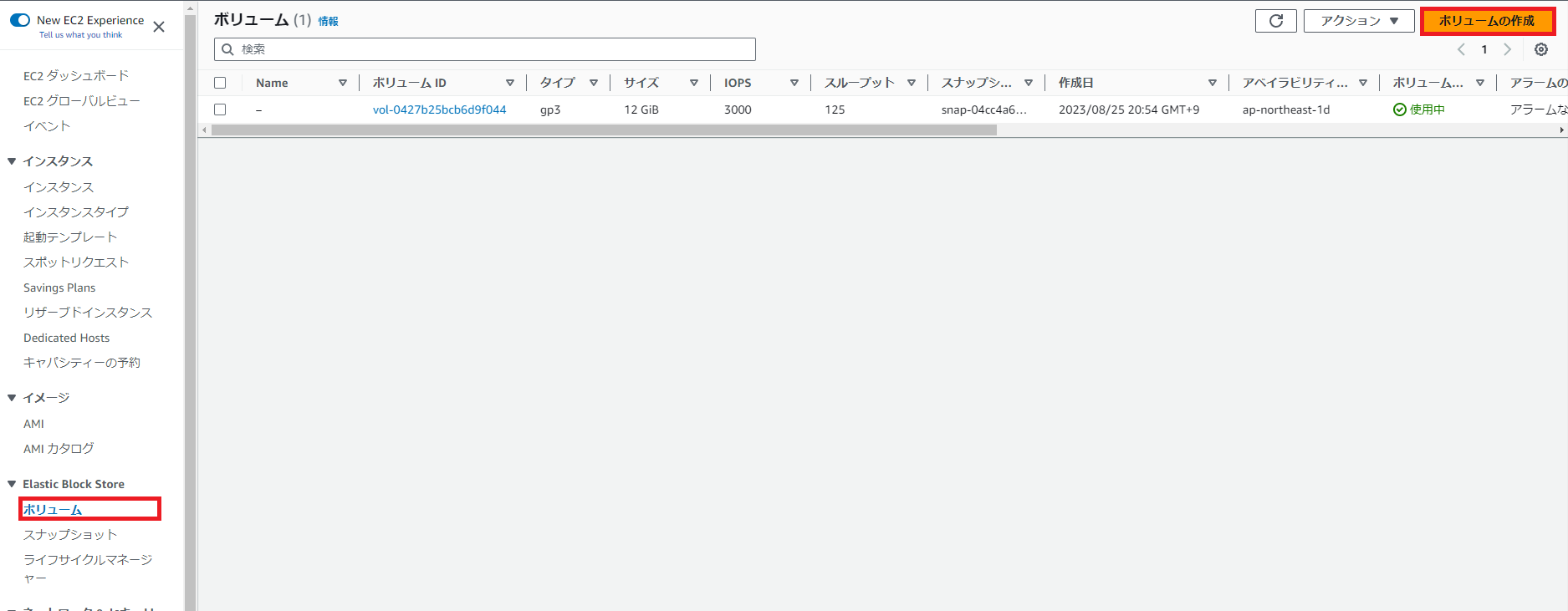
ボリュームを8GBで作成する。 ※アベイラビリティゾーンに気をつけること
作業用のインスタンスを作成する
下記で作成する。
| 項目 | 設定値 |
|---|---|
| 名前 | work-instance |
| OS | AmazonLinux2023 AMI |
| アーキテクチャ | 64ビット(Arm) |
| インスタンスタイプ | t4g.nano |
| キーペア | web-server |
| セキュリティグループ | ssh (自分のIPのみ) |
| ストレージ | 8GB (gp3) |
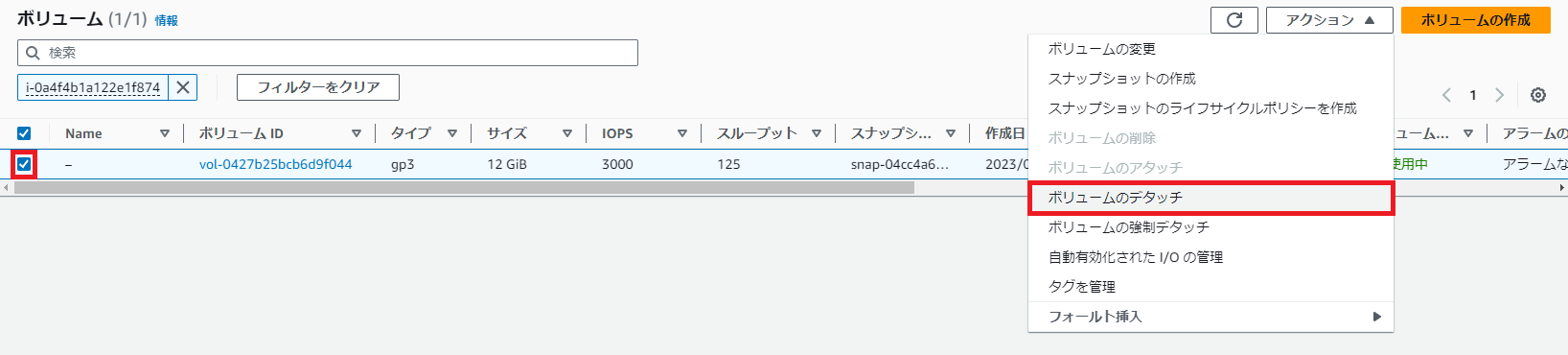
対象のインスタンスを停止し、ボリュームをデタッチする
インスタンスから アクション > インスタンスを停止を選択する。

対象のインスタンスのIDを控え、ボリュームで検索する。
ボリュームから アクション > ボリュームのデタッチを選択する。
作業用のインスタンスに新ボリュームと旧ボリュームをアタッチする
ボリュームからアクション > ボリュームのアタッチを選択する。
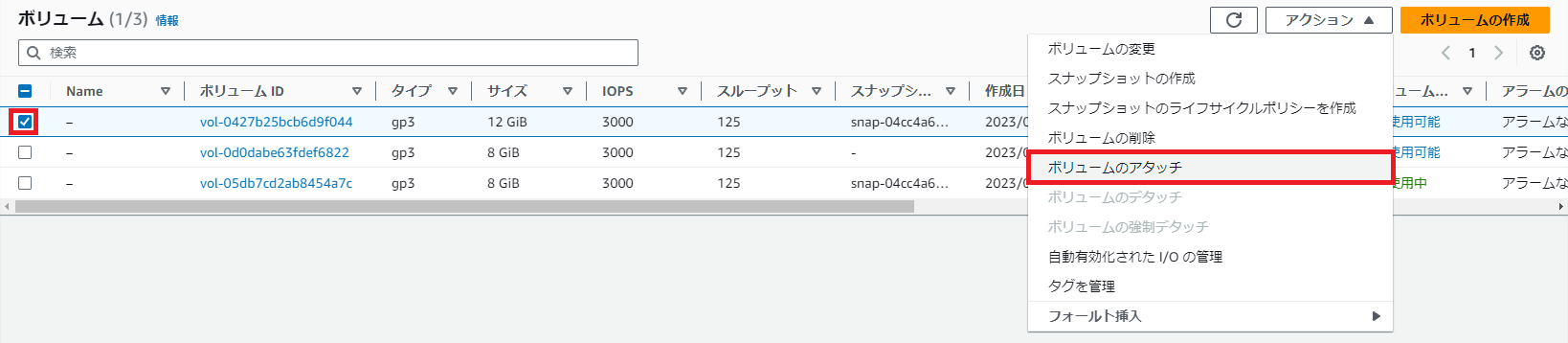
ボリュームのアタッチで対象のインスタンスを選択し、ボリュームのアタッチを選択する。
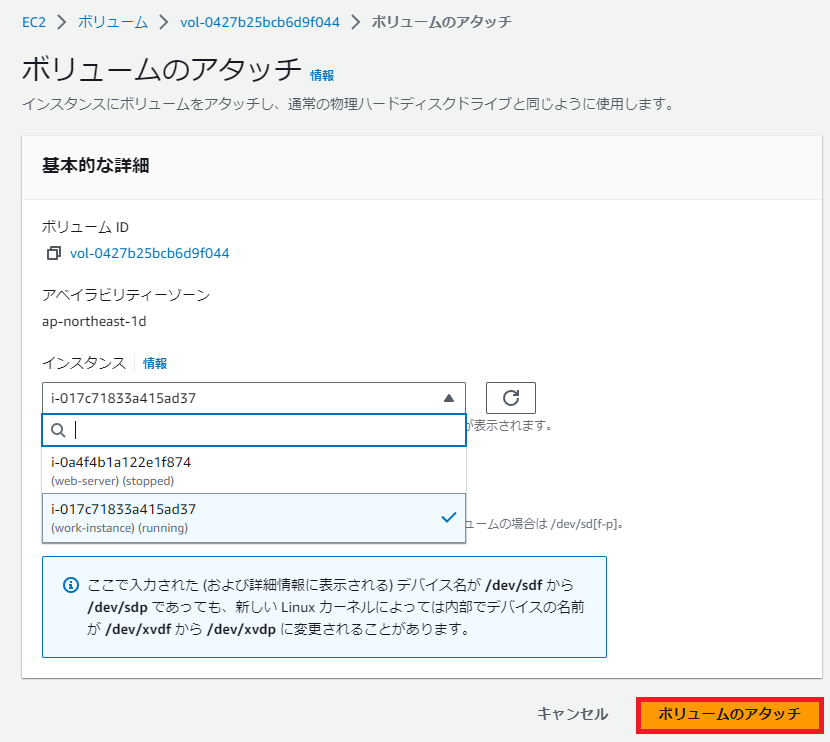
※もう一つのボリュームも同じ手順でアタッチする。
作業用のインスタンスにログインし、旧ボリューム(12GB) と 新ボリュームのディスクで同期を取る
SSHで対象のインスタンスにログインをする。lsblkでディスクを確認する。
[ec2-user@ip-172-31-37-241 ~]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
nvme1n1 259:0 0 12G 0 disk
├─nvme1n1p1 259:2 0 12G 0 part /
└─nvme1n1p128 259:3 0 10M 0 part
nvme0n1 259:1 0 8G 0 disk
├─nvme0n1p1 259:4 0 8G 0 part
└─nvme0n1p128 259:5 0 10M 0 part
nvme2n1 259:6 0 8G 0 disk fdisk -l /dev/nvme1n1で古いボリュームの情報を表示する。
[ec2-user@ip-172-31-37-241 ~]$ sudo fdisk -l /dev/nvme1n1
Disk /dev/nvme1n1: 12 GiB, 12884901888 bytes, 25165824 sectors
Disk model: Amazon Elastic Block Store
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: 9EEB8434-C088-40E5-8C9E-46F9A237FA80
Device Start End Sectors Size Type
/dev/nvme1n1p1 22528 25165790 25143263 12G Linux filesystem
/dev/nvme1n1p128 2048 22527 20480 10M EFI System
Partition table entries are not in disk order.- ブート パーティションを古いルート ボリューム
nvme1n1から新しいルート ボリュームnvme2n1にコピーする
dd if=/dev/nvme1n1 of=/dev/nvme2n1 bs=512 count=24576[root@ip-172-31-37-241 ec2-user]# dd if=/dev/nvme1n1 of=/dev/nvme2n1 bs=512 count=24576
24576+0 records in
24576+0 records out
12582912 bytes (13 MB, 12 MiB) copied, 1.52274 s, 8.3 MB/sif: 入力ファイル/デバイス; 古いルートボリューム。of: 出力ファイル/デバイス; 新しいルートボリューム。bs: バイト単位のブロック サイズ。これはセクターサイズと同じcount: コピーするブロックの量; これは、(最初の) データ パーティションの開始セクターと等しくなる。
- 古いボリュームのUUIDを表示する。 (これは控えておく)
[root@ip-172-31-37-241 ec2-user]# blkid /dev/nvme1n1p1
/dev/nvme1n1p1: LABEL="/" UUID="6bc0fdc0-ccc5-4301-89d9-b7a2cd0a2c67" BLOCK_SIZE="4096" TYPE="xfs" PARTLABEL="Linux" PARTUUID="f7cda471-6c2a-4e59-b64d-6c10c894b2bf"6bc0fdc0-ccc5-4301-89d9-b7a2cd0a2c67 を控える。
gdiskを実行し、新しいボリュームの更新をする
gdisk /dev/nvme2n1パーティション テーブル (GPT) を調整する
Command (? for help): x
Expert command (? for help): e
Relocating backup data structures to the end of the diskメニューに戻る
Expert command (? for help): m古いデータ パーティションを削除する
Command (? for help): d
Partition number (1-128): 1正しいサイズで新しいデータ パーティションを作成する。
Command (? for help): n
Partition number (1-128, default 1): 1
First sector (34-16777182, default = 22528) or {+-}size{KMGTP}: 22528
Last sector (22528-16777182, default = 16777182) or {+-}size{KMGTP}: 0
Current type is 8300 (Linux filesystem)
Hex code or GUID (L to show codes, Enter = 8300):
Changed type of partition to 'Linux filesystem'↓ First sector は、これの /dev/nvme1n1p1 の Start の部分
Device Start End Sectors Size Type
/dev/nvme1n1p1 22528 25165790 25143263 12G Linux filesystem
/dev/nvme1n1p128 2048 22527 20480 10M EFI System変更をディスクに書き込む
Command (? for help): w
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y
OK; writing new GUID partition table (GPT) to /dev/nvme2n1.
The operation has completed successfully.- 新しいボリューム
dev/nvme2n1p1に xfsファイルシステムを作成する
mkfs -t xfs -f /dev/nvme2n1p1- マウント先を作成する。
sudo mkdir -p /mnt/web-server-origin
sudo mkdir -p /mnt/web-server-new- マウントを実行する。
sudo mount -t xfs -o nouuid /dev/nvme1n1p1 /mnt/web-server-originsudo mount -t xfs -o nouuid /dev/nvme2n1p1 /mnt/web-server-newrsyncコマンドで同期を実施する。
sudo rsync -axvP --delete /mnt/web-server-origin/ /mnt/web-server-new/sent 1,863,625,623 bytes received 806,968 bytes 55,654,704.21 bytes/sec
total size is 1,860,315,090 speedup is 1.00同期完了したので確認をする。
web-server-new を確認する。
[root@ip-172-31-37-241 web-server-new]# ls
bin dev home lib64 media opt root sbin sys usr
boot etc lib local mnt proc run srv tmp var良さそう。
- 新しいルートボリューム上の (最初の) データ パーティションの UUID と LABEL を更新して、古いルート ボリュームの値と一致させる
sudo umount /mnt/web-server-origin /mnt/web-server-newxfs_admin -U 6bc0fdc0-ccc5-4301-89d9-b7a2cd0a2c67 /dev/nvme2n1p1
xfs_admin -L / /dev/nvme2n1p1[root@ip-172-31-37-241 ec2-user]# blkid /dev/nvme1n1p1
/dev/nvme1n1p1: LABEL="/" UUID="6bc0fdc0-ccc5-4301-89d9-b7a2cd0a2c67" BLOCK_SIZE="4096" TYPE="xfs" PARTLABEL="Linux" PARTUUID="f7cda471-6c2a-4e59-b64d-6c10c894b2bf"
[root@ip-172-31-37-241 ec2-user]# sudo umount /mnt/web-server-origin /mnt/web-server-new
[root@ip-172-31-37-241 ec2-user]# xfs_admin -U 6bc0fdc0-ccc5-4301-89d9-b7a2cd0a2c67 /dev/nvme2n1p1
Clearing log and setting UUID
writing all SBs
new UUID = 6bc0fdc0-ccc5-4301-89d9-b7a2cd0a2c67
[root@ip-172-31-37-241 ec2-user]# xfs_admin -L / /dev/nvme2n1p1
writing all SBs
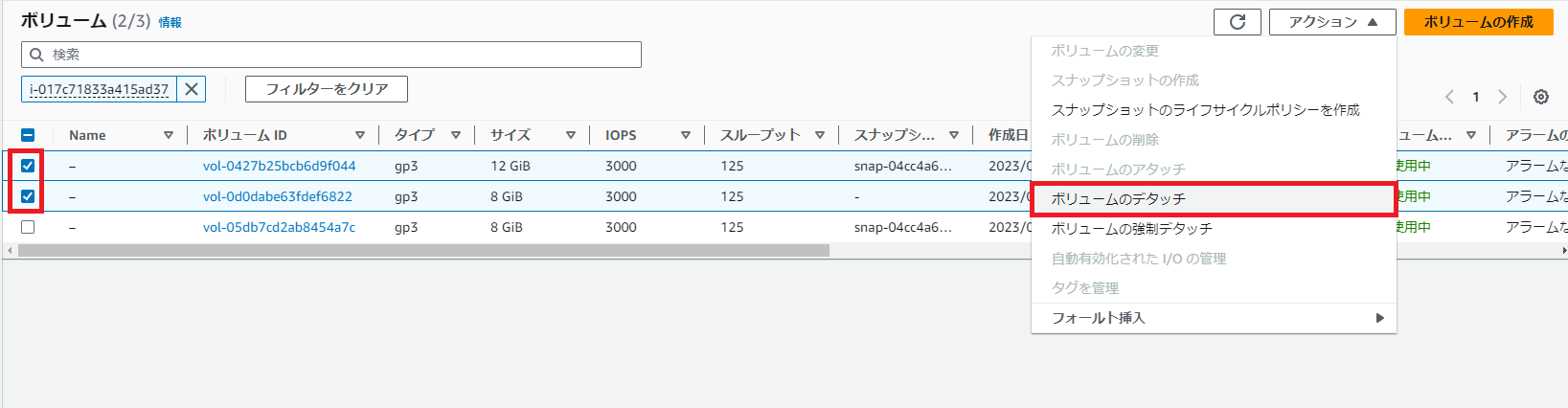
new label = "/"作業用のインスタンスを停止し、旧ボリュームと新ボリュームをデタッチする。
インスタンスから アクション > インスタンスを停止を選択する。

対象のインスタンスのIDを控え、ボリュームで検索する。

※ /dev/xvda はルートボリュームなので、これはそのままにしておく。
- ボリュームから アクション > ボリュームのデタッチを選択する。
対象のインスタンスに新ボリュームをアタッチし、ルートボリュームとして起動するようにする
ボリュームからアクション > ボリュームのアタッチを選択する。
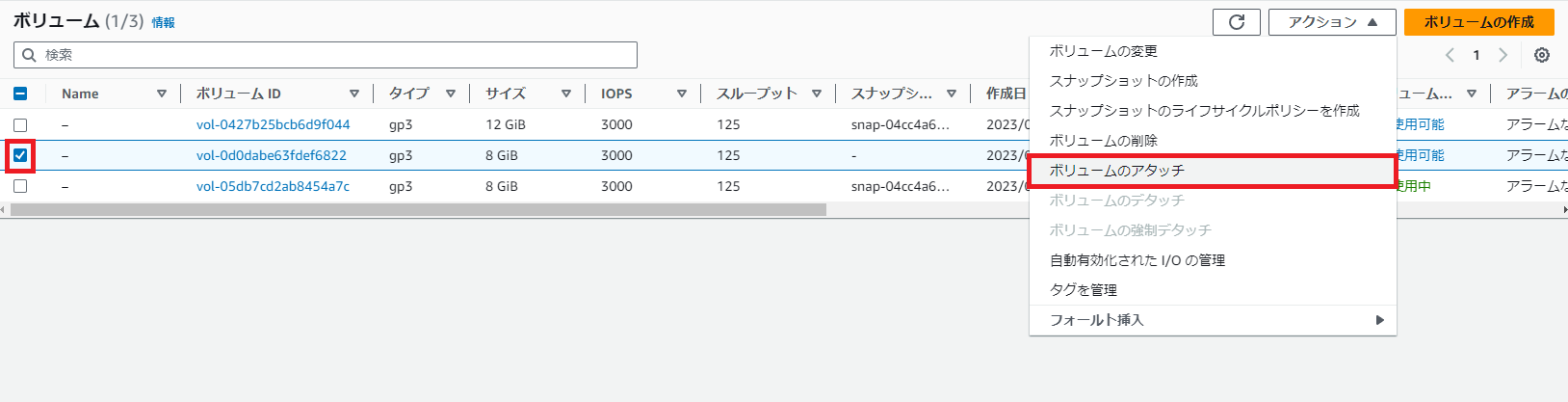
ボリュームのアタッチで対象のインスタンスを選択し、ボリュームのアタッチを選択する。
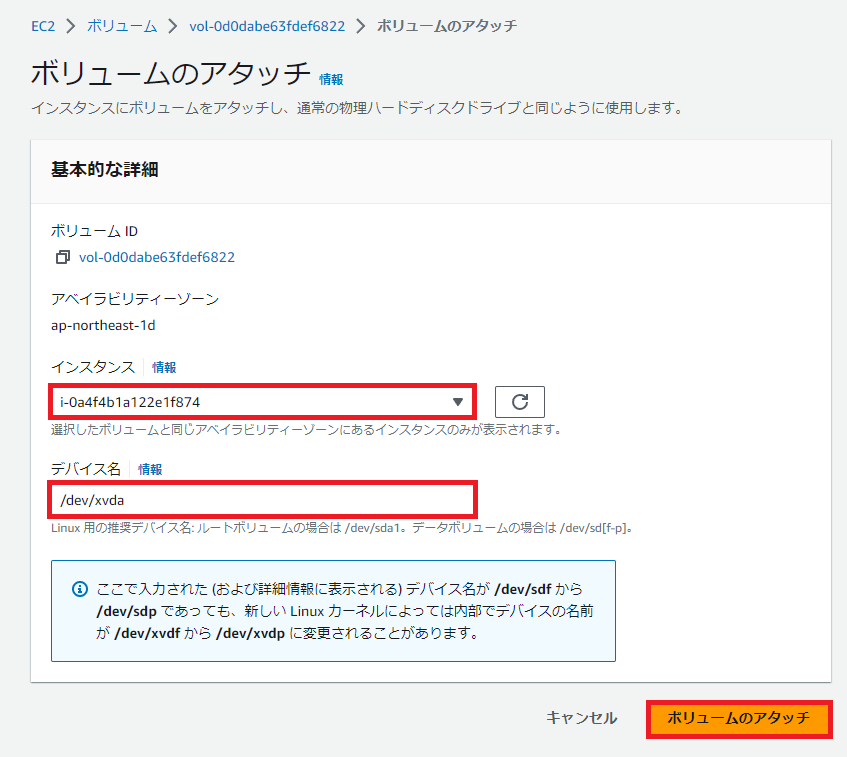
※ルートボリュームとして /dev/xvda を指定すること
web-serverを起動する。
できたあああああ
参考
- How to Shrink an EBS Root Volume (XFS) on Amazon Linux 2 / 2023
https://medium.com/@benedikt.langens/how-to-shrink-an-ebs-root-volume-xfs-on-amazon-linux-2-2023-a7705c16e839 - (ルートボリュームな)EBSの容量を縮小してみた
https://blog.denet.co.jp/reduced-ebs-capacity/ - 「EBSのサイズ減らして!」と言われたときにサッと対応する
https://study-infra.com/aws-ebs-shrink/ - Linux で Amazon EBS ボリュームを使用できるようにする
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ebs-using-volumes.html - curlで「Couldn’t resolve host」エラーが出た場合の対処
https://qiita.com/bz0/items/7d4bac34c6cdada59b94 - Fedora 35 をBIOS/MBRからGPT/UEFIの起動に切り替えた際のメモ
https://qiita.com/KazuFurutaka/items/113111a8e9711b1c84fd
おわりに
最初は、grub2-install とかで、ブートローダのUUIDを更新する方針でやっていたがどうやってもできなかった。
解決しても起動してくれないので、これOSが新しくなってブートローダの機構も違うのでこのあたりの手順は使えないのでは…と考えた。
なので、amazonlinux2023 ebs volume shrink とかで検索をかけてみたところ、https://medium.com/@benedikt.langens/how-to-shrink-an-ebs-root-volume-xfs-on-amazon-linux-2-2023-a7705c16e839 の素晴らしいサイトに出会った。
この手順で実施したところできました…!ありがとうございます…!
EBSのルートボリュームの縮小大変すぎるので、ちゃんと見積もりはしたほうが良いですね…。本当に面倒くさい。