はじめに
今回は Ollama + Next.js + VOICEVOX を組み合わせて、ローカル環境で完結する面接練習アプリを作ってみた。
成果物はこちら。
環境
- Node.js 20+
- Next.js 16 (App Router)
- TypeScript 5
- VOICEVOX Engine
- Ollama (`gemma3:4b`)
- Chrome or Edge (Web Speech APIの利用)作ろうと思った背景
就職活動をしている中で、面接の受け答えを声に出して練習する時間を増やしたいと考えていた。
ただ、自分は話すのがあまり得意ではなく、いきなり人との模擬面接だと心理的なハードルが高い。 そのため、まずはAIを相手に壁打ちできる環境を用意することにした。
最初はテキストだけの構成も考えたが、どうしても味気なく続かなかった。 そこで、ずんだもんの音声と立ち絵を組み合わせて、会話らしさを持たせる方針とした。
作ったもの
アプリは「質問を受ける -> 音声で答える -> 最後に評価を受ける」という流れである。
- 面接質問数を選ぶ
- ずんだもんが質問を読み上げる
- マイク入力で回答する
- 全質問終了後にOllamaが評価とコメントを返す
ローカルで完結するため、外部APIキーなしで試しやすいのも良かった点である。
画面は以下のような感じ。

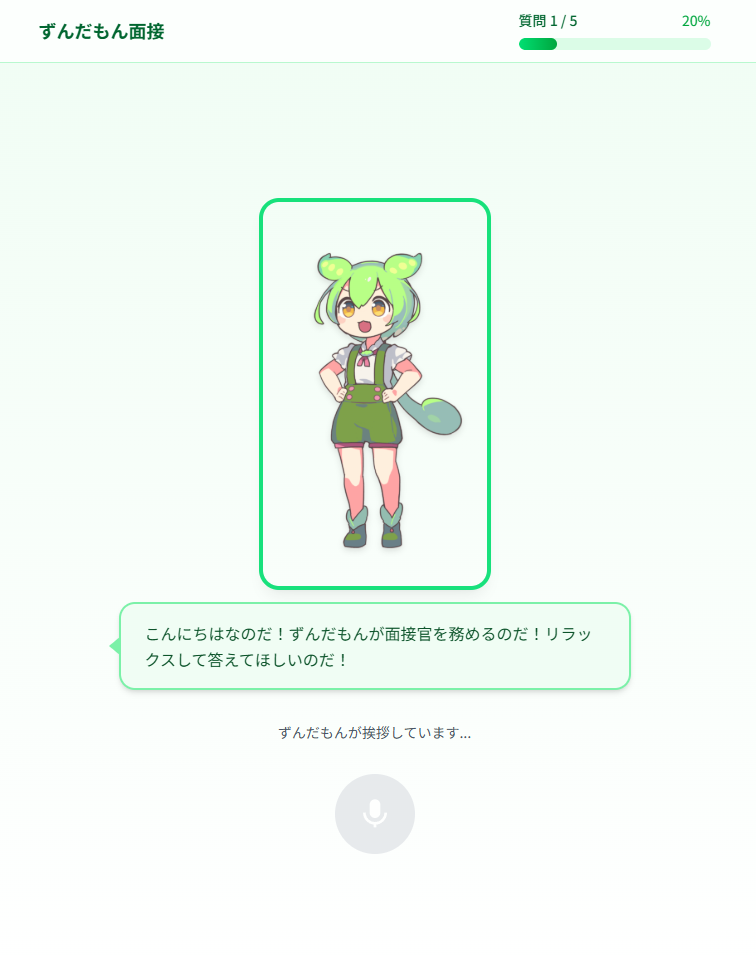
ローカル実行手順
READMEに沿って、git clone から実行する手順を記載する。
まず、前提条件は以下。
- Git がインストールされていること
- Docker / Docker Compose がインストールされていること
リポジトリを取得し、作業ディレクトリへ移動する。
git clone https://github.com/katsuobushiFPGA/ai-voicevox-interview.git
cd ai-voicevox-interviewその後、Docker Composeでまとめて起動する。
docker compose up -d初回はOllamaモデルのダウンロードが入るため、少し時間がかかる。
起動後に http://localhost:3000 へアクセスして動作確認できる。
ローカル開発モードで試す場合は、VOICEVOX Engine と Ollama を別途起動した上で次を実行する。
npm install
npm run dev環境変数の例は以下の通り。
VOICEVOX_BASE_URL=http://localhost:50021
OLLAMA_BASE_URL=http://localhost:11434
OLLAMA_MODEL=gemma3:4bアプリの構成
全体構成は以下の通り。
フロントエンドはブラウザで完結しつつ、音声合成と評価処理をそれぞれ VOICEVOX と Ollama に分離する構成にしている。
面接1セッションの処理フローは以下の通り。
作ってみた感想
正直、今回は「ここが本当にきつかった」という場面はほぼなかった。 Claude Opus 4.6 を使って実装を進めたことで、細かい詰まりを短時間で解消できたのが大きい。
改善したいところとして、評価計算の部分にかなり時間がかかっているところがある。
これはモデルの性能なのか、プロンプト設計の問題なのかはまだ分析できていない。
学びになったのは、技術の難しさもそうだが体験設計の比重であった。
面接練習アプリの場合、精度も大事ではあるが「続けたくなる雰囲気」を作ることが重要だと感じた。
※テキストだけだと味気ないので、ずんだもんの音声と立ち絵を組み合わせたところ楽しさ的なものができたので、VRMモデルを組み合わせるのも面白そうだと感じた。
基本は、自分が喋れているかを確認するためのアプリで作ったのだけど、興が乗ればずんだもんと会話するような体験にしても面白いかもしれないなぁと思った。
参考
Next.js Documentation
https://nextjs.org/docsVOICEVOX
https://voicevox.hiroshiba.jp/Ollama
https://ollama.com/Web Speech API
https://developer.mozilla.org/en-US/docs/Web/API/Web_Speech_API
おわりに
就活向けの面接練習をテーマに、ローカルLLMと音声合成を組み合わせたアプリを作ってみた。 同じように「まずはひとりで壁打ちしたい」人には、ローカル完結の構成は相性が良いと感じる。